Linear Regression & Neuronal Network
A full-stack application for training and visualizing a linear regression model and a neuronal network using C++, Node.js, and React.
Overview
This project brings together high-performance C++ computing with a modern web application, making it ideal for both education and rapid prototyping. It features analytical Linear Regression and a customizable Feedforward Neural Network, both implemented in C++11 and seamlessly integrated with a Node.js/Express backend. The frontend, built with React, utilizes REST APIs and WebSockets to provide dynamic visualizations of data points, regression lines, training losses, and predictions in real-time.
Tech Stack
C++ Engine
- Language: C++11
- Build System: GNU Make
- Libraries: STL, OpenMP (for optional parallelization)
- Features: High-performance mathematical operations, parallelized training
Backend Server
- Runtime: Node.js
- Framework: Express for REST API endpoints
- Communication:
- WebSocket (ws) for live data streaming
- child_process.spawn for C++ binary execution
- Features: Bridges C++ computations with frontend, streams real-time training data
Frontend Client
- Framework: React (via create-react-app)
- Styling: Tailwind CSS with DaisyUI components
- Visualization: Chart.js for interactive data visualization
- Communication: WebSocket API for real-time updates
- Features: Interactive UI for data input, model configuration, and results display
Build & Development Tools
- Build Tools: GNU Make, npm, Node.js
- Platform Support: Cross-platform (Windows via MinGW, macOS, Linux)
- Development: Hot-reloading for rapid iteration
Getting Started
1. Clone the repository
git clone https://github.com/Nicolas2912/cpp-ml-react.git
cd cpp-ml-react
2. Build the C++ engine
cd cpp
make # Creates linear_regression_app (or .exe on Windows)
cd ..
3. Run the backend server
cd server
npm install
npm start
# Server runs on http://localhost:3001
4. Launch the frontend client
# Open a new terminal
cd client
npm install
npm start
# Opens at http://localhost:3000
Usage
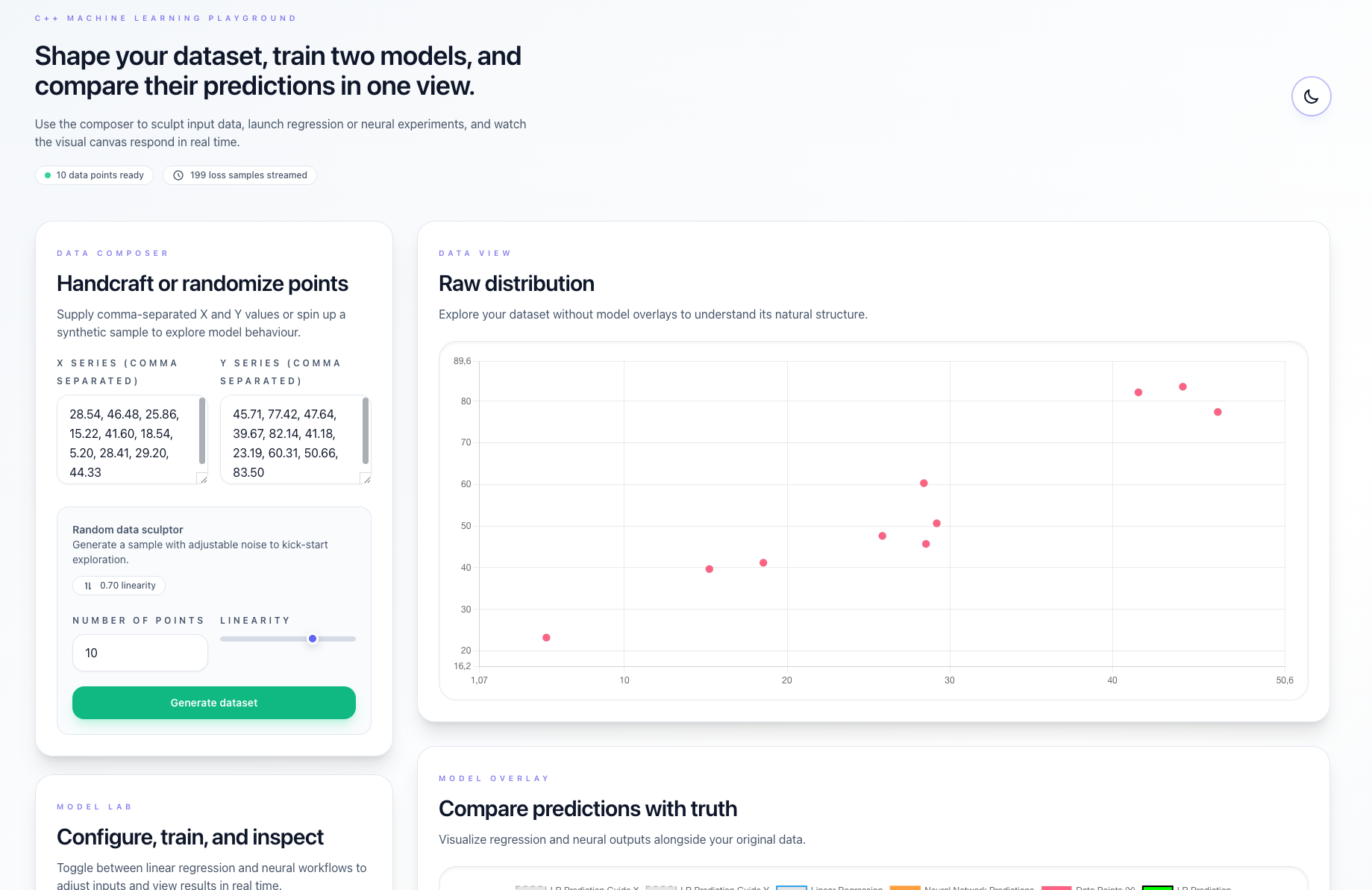
Data Input and Generation
- Manual Input: Enter comma-separated X/Y data points
- Random Generation: Generate data by specifying:
- Number of points
- Desired linearity (noise level)
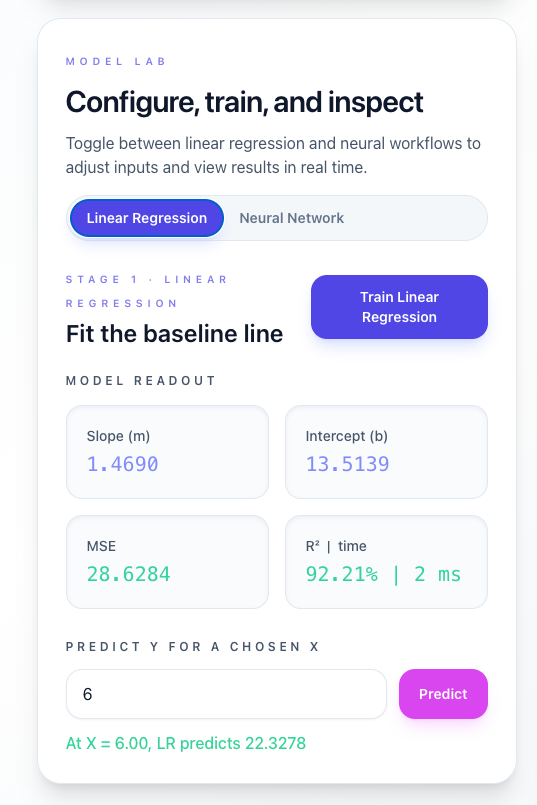
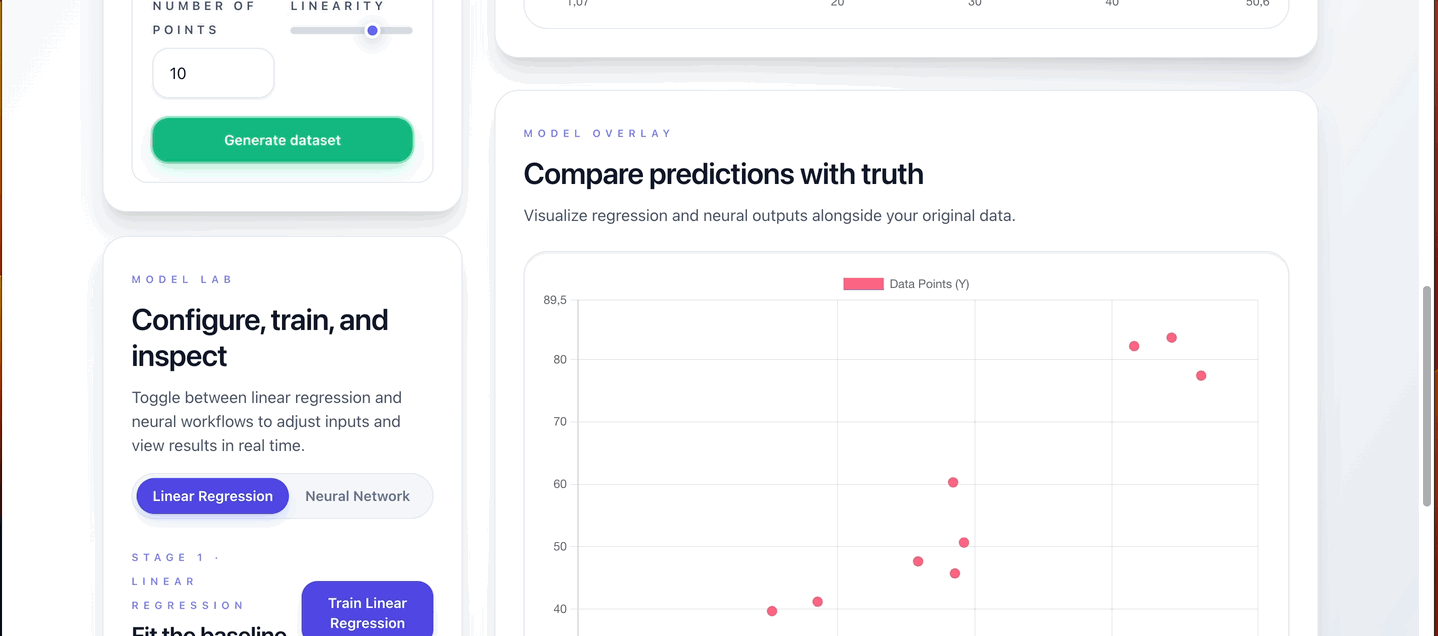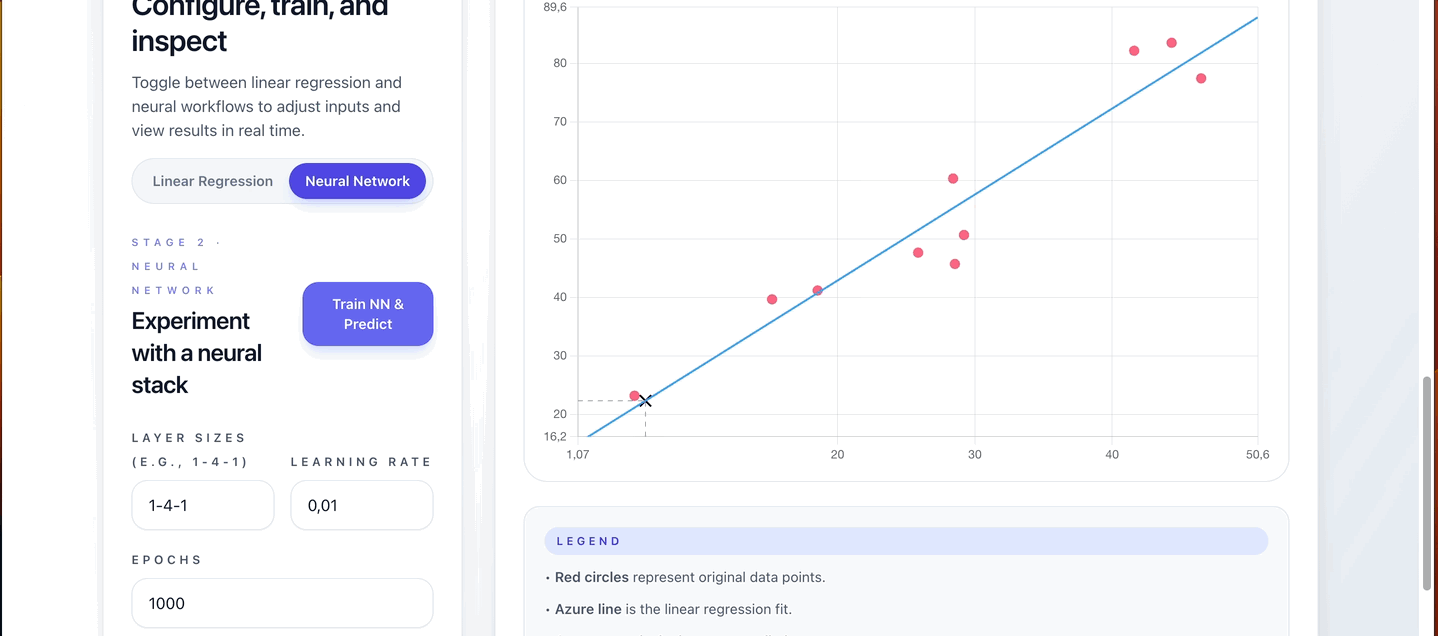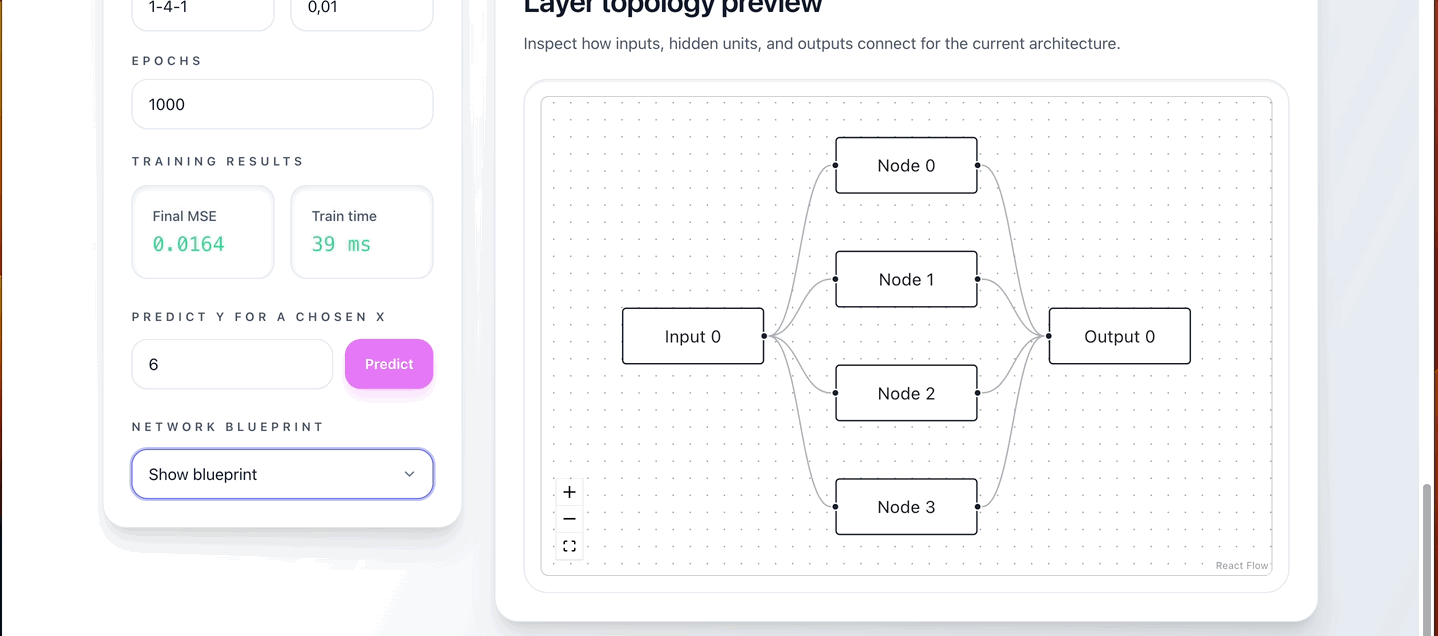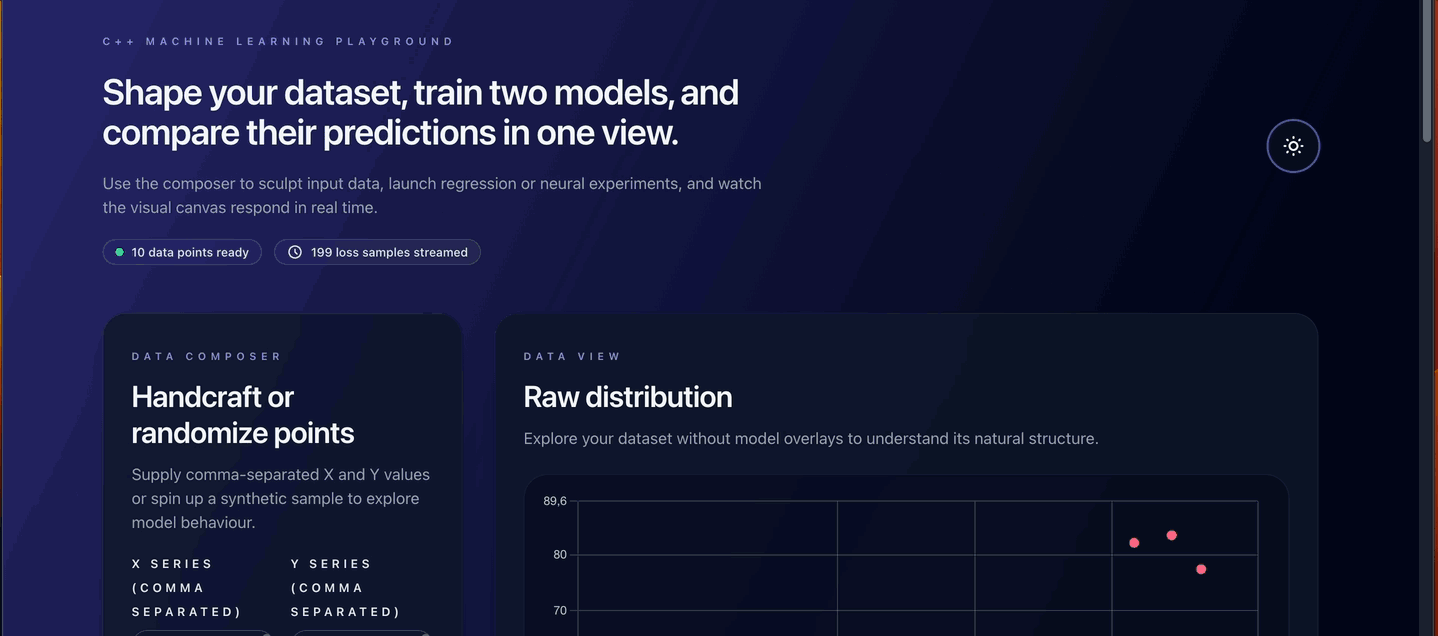
Linear Regression Training
- Click “Train Linear Regression”
- Review results:
- Slope and intercept coefficients
- Mean Squared Error (MSE)
- R² (coefficient of determination)
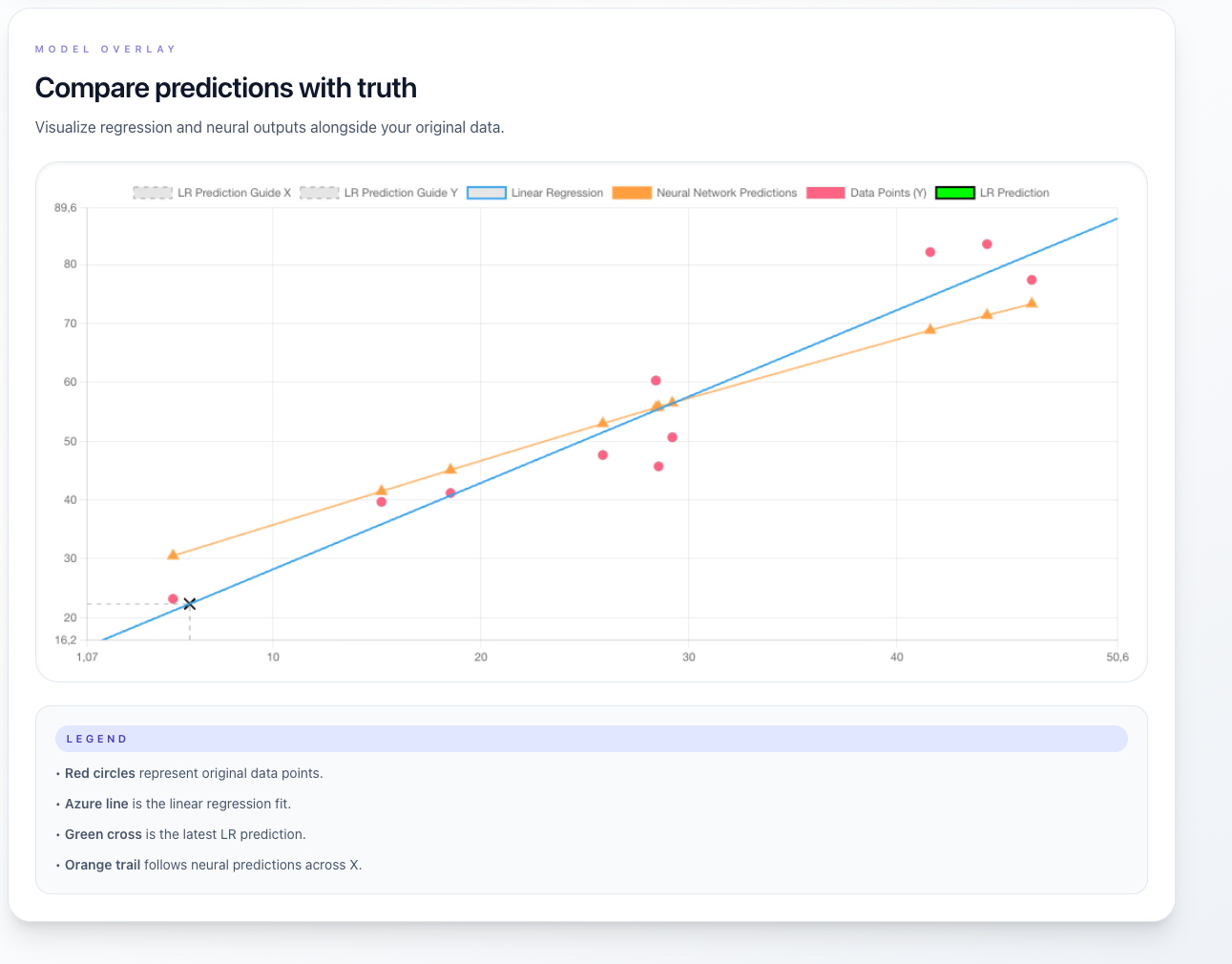
- Visualize the regression line on the scatter plot
- Predict new Y-values using the input box
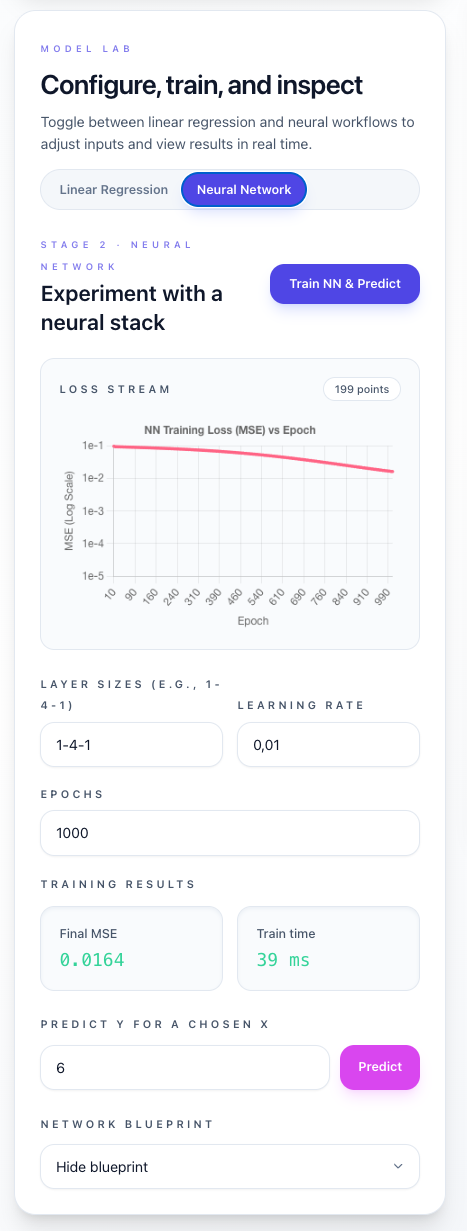
Neural Network Training
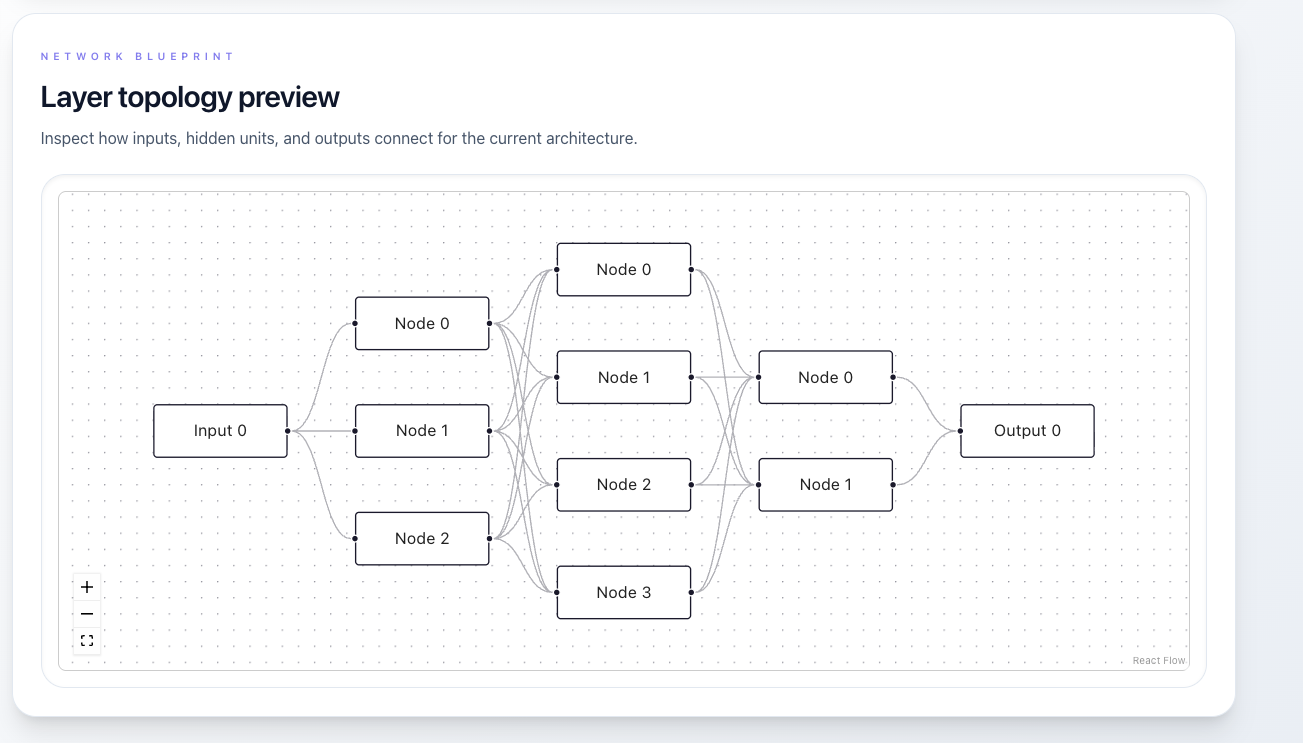
- Configure your network:
- Layer architecture (e.g., 1-4-1)
- Learning rate
- Number of training epochs
- Click “Train NN & Predict”
- Monitor real-time training loss via WebSockets
- Review final predictions, MSE, and total training time
Interactive Features
- Toggle between dark and light themes
- Hover over data points for detailed information
- Use tooltips to understand training metrics
Architecture & Components
C++ Engine (cpp/)
linear_regression.h/.cpp:- Implements linear regression using the normal equation
- Computes performance metrics (MSE, R²)
neural_network.h/.cpp:- Defines feedforward neural network architecture
- Implements sigmoid activation functions
- Performs training via gradient descent optimization
main_server.cpp:- Provides CLI interface for training commands
- Handles data streaming to Node.js backend
Makefile:- Builds C++ modules into executable binaries
- Configures optimization and parallel support
Backend Server (server/)
server.js:- Manages REST API endpoints
- Executes C++ subprocesses
- Parses computation output
- Streams data via WebSockets
- Handles cross-platform execution differences
- Dependencies:
- cors for cross-origin requests
- ws for WebSocket communication
Frontend Client (client/)
- React components for:
- Data input and visualization
- Model configuration
- Training controls
- Real-time charts
- Styled with Tailwind CSS and DaisyUI for responsive UI
Additional Components
build/: IDE and debugging artifactstest_openmp.cpp: Utility for verifying OpenMP parallel capabilities- Root-level binaries: Pre-compiled executables for quick demos
Challenges
Throughout this project, I encountered three major challenges that pushed me to deepen my understanding of both C++ and full-stack JavaScript development. Below I describe each challenge, how I solved it in my actual implementation, why I chose that approach, and ways I might improve it in the future.
1. Bridging C++ and Node.js
I needed to run high-performance C++ code (both an analytical linear-regression solver and a custom neural network with backpropagation) from a Node.js backend without sacrificing productivity or maintainability.
Implemented Solution
- Compiled my C++ logic into standalone executables (
linear_regression_appand the combinedmain_serverfor both LR and NN). - In
server/server.js, I use Node’schild_process.spawnto launch the appropriate C++ binary with commands likelr_trainornn_train_predict. - Data is passed via
stdinas simple comma-separated lines (e.g.1,2,3,4\n2,4,6,8\n), and output is printed line-by-line in the formkey=value. - A helper function
parseCppLine(line)splits each line into{ type: 'loss_update', epoch, mse }or{ type: 'final_stat', key, value }, which I then transform into JSON messages for HTTP responses and WebSocket broadcasts.
Why This Approach
- Simplicity: Using standard I/O and a text-based protocol meant zero extra dependencies on the C++ side beyond the STL.
- Decoupling: C++ remains a pure console application; Node.js does all orchestration and parsing in JavaScript.
- Portability: No need to learn N-API or maintain native addons; the same binaries can be invoked from any language or environment that can spawn processes.
Future Improvements
- Replace the line-based protocol with a more robust serialization format (e.g. JSON or Protocol Buffers) to avoid parsing edge cases.
- Explore writing a true Node addon (via N-API) for tighter integration and lower latency once the prototype is stable.
2. Real-time Loss Streaming Over WebSockets
During neural-network training, I print loss after every epoch. For small datasets or many epochs, this floods the WebSocket channel and causes UI lag or even browser buffer overflows.
Implemented Solution
- In
server.js, every time C++ writes a line likeepoch=42,mse=0.1234, I broadcast an object{ type: 'loss_update', epoch, mse }to all connected WebSocket clients. - On the React frontend (
App.js), I collect incoming updates into a local batch (lossUpdateBatchRef). - I use
lodash.throttleto call a batched updater at most once every 150 ms. That function-
Merges new points (filtering out duplicates) into React state,
-
Clears the batch,
-
Directly calls
chartRef.current.update('none')on the Chart.js instance to redraw without animation.
-
- When I receive the final result or an error (
type: 'final_result'/type: 'error'), Iflush()the throttle to process any remaining batches immediately.
Why This Approach
- Performance: Throttling prevents React from re-rendering hundreds or thousands of chart points per second.
- Responsiveness: Manual chart updates (
'none') eliminate animation overhead and keep the graph in sync with minimal flicker. - Reliability: Batching + flush ensures no messages are dropped, even if they arrive faster than the throttle interval.
Future Improvements
- Implement server-side buffering or dynamic
report_every_n_epochs(configurable via the API) to reduce network chatter. - Provide visual feedback (e.g. a progress bar) so users know training is ongoing even when loss updates pause.
- Explore binary protocols over WebSocket (e.g. MessagePack) for even lower overhead.
3. Correct Neural-Network and Backpropagation in C++
Writing a fully-featured backpropagation algorithm from scratch in C++ — complete with flexible layer sizes, safe matrix/vector arithmetic, and periodic loss reporting—is a nontrivial undertaking.
Implemented Solution
- Created a
NeuralNetworkclass (neural_network.h/.cpp) that:-
Stores
layer_sizes_, a vector of weights matrices, and bias vectors. -
Initializes weights with a simple He-style scaling (
±0.5/√n) and small positive biases. -
Implements
forward_passto compute weighted sums (z) and applysigmoidon hidden layers, identity on the output. -
Stores both pre-activation (
layer_inputs_) and post-activation (layer_outputs_) vectors to simplify gradient computation. -
Implements
backpropagateby-
Computing output-layer delta as
(ŷ – y), -
Back-propagating through each hidden layer via transposed weight multiplication plus
sigmoid_derivative(z), -
Applying stochastic gradient descent updates to weights (
W ← W – η ⋅ δ⋅aᵀ) and biases.
-
-
Exposes
train_for_epochs(inputs, targets, epochs)that shuffles data each epoch, runsbackpropagateon every sample, and printsepoch=<n>,mse=<value>whenever(epoch+1)%report_every_n_epochs==0or at the last epoch. -
After training, returns a flat vector of final predictions for all inputs, allowing the caller to compute and print
final_mse,training_time_ms, andnn_predictions=….
-
Why This Approach
- Clarity: Separating forward/backward logic into clear methods makes it easier to debug each stage.
- Reusability: The same
train_for_epochsmethod handles both loss reporting (for streaming) and final prediction output. - Control: Writing my own vector/matrix routines lets me ensure correctness before introducing an external linear-algebra dependency.
Future Improvements
- Swap out the home-grown matrix/vector code for a high-performance library (e.g. Eigen or BLAS) to accelerate large networks.
- Support additional activation (ReLU, tanh) and loss functions (cross-entropy) for wider applicability.
- Add mini-batch gradient descent, momentum, and adaptive learning-rate schedulers to improve convergence on larger datasets.
Tackling these challenges significantly improved my skill with low-level C++ (especially designing and debugging the backprop algorithm) and my ability to architect a full-stack pipeline that stitches native code into a smooth, real-time web experience.
What I learned
Building this end-to-end C++ ↔ Node.js pipeline and live-streaming neural-network demo taught me invaluable lessons in both low-level systems programming and high-level web architecture:
-
Process Communication & Protocol Design
-
I now feel comfortable using
child_process.spawnin Node.js to launch native binaries, pipe data intostdin, and read bothstdoutandstderras streaming events. -
Designing a minimal text protocol—printing
key=valuepairs line by line from C++ and parsing them in JavaScript via a single helper (parseCppLine)—proved both robust and easy to debug. -
I learned to guard against edge cases: always ending the C++ stdin stream (
cppProcess.stdin.end()), checking forres.headersSentbefore writing HTTP responses, and handling non-zero exit codes or parse failures gracefully.
-
-
Real-Time Streaming Over WebSockets
-
Integrating the
wslibrary on the server and a rawWebSocketin React gave me a front-row seat to the challenges of high-frequency updates. -
I discovered that unthrottled epoch-by-epoch messages overwhelm the browser, so batching them in a
useRefqueue and usinglodash.throttle(150 ms) to update React state is critical for smooth chart rendering. -
Directly calling
chartRef.current.update('none')on the Chart.js instance taught me how to decouple data ingestion from animated redraws, ensuring a snappy UI even under load. -
Properly cleaning up on unmount—calling
scheduleProcessLossBatch.cancel(), closing sockets inuseEffectcleanup, and clearing batches—prevented subtle memory leaks and dangling callbacks.
-
-
Implementing Backpropagation in C++
-
Writing a full
NeuralNetworkclass from scratch solidified my understanding of forward passes, storing pre-activation inputs (z) and post-activation outputs (a), and computing deltas layer by layer. -
I sharpened my C++ skills: • Exception-safe parsing with
std::strtodand thorough error checks inparseVectorandparseLayerSizes. • Random weight initialization usingstd::mt19937with scaled uniform distributions. • Timing code precisely with<chrono>to reporttraining_time_ms. -
Separating algorithm (
train_for_epochs) from I/O (main_server.cpp) made both sides easier to test and maintain. I now appreciate the discipline of throwing on invalid matrix dimensions and catching every parsing exception at the top level.
-
-
Full-Stack Architecture & Tooling
-
I gained confidence wiring together a JavaScript REST/WebSocket layer (Express + ws) with a React front end (react-chartjs-2, reactflow) and a C++ numerical engine. Clear separation of concerns kept each component focused—Node.js orchestrates processes and handles HTTP/WebSocket clients, React manages state and visuals, and C++ crunches numbers.
-
Detailed logging became my best friend: streaming chunks of C++ stdout/stderr to Node’s console, emitting structured logs (
LR Train C++ Stdout Chunk,WebSocket message received), and surfacing errors early made multi-language debugging tractable. -
I reinforced best practices around input validation (both in JS and C++), error propagation, and defensive cleanup—skills that will pay dividends in any large-scale system.
-
Next Steps
- Standardize the IPC protocol (e.g. JSON or Protocol Buffers over stdin/stdout) to eliminate ad-hoc parsing.
- Experiment with writing a native Node.js addon (N-API) for tighter, lower-latency C++ integration once the prototype stabilizes.
- Extend the neural-network code with mini-batch training, momentum, and alternative activations, and benchmark it against existing libraries for performance and accuracy.
Improvements I’d Like to Make
-
GPU Acceleration: Implement CUDA kernels for parallel training of neural networks, potentially yielding 10-100x speedup for large problem instances.
-
Other optimizer: Implement other optimization algorithms (e.g. Adam, RMSprop) to improve convergence and performance.
-
Other activation function: Implement other activation functions (e.g. ReLU, tanh) to improve performance.
Screenshots